

Tự chế tạo một siêu máy tính
W.W. Hargrove, F.M. Hoffman, T. Sterling
(người dịch numeric)
Trong câu chuyện ngụ ngôn nổi tiếng "cháo rừu" (hay "cháo đá"), một anh lính lang thang dừng chân tại một làng quê nghèo và nói với mọi người ở đây rằng anh ta sẽ nấu được món cháo ngon tuyệt chỉ với nuớc sôi và một cái rừu sáng bóng. Dân làng ban đầu nghi ngờ nhưng rồi cũng mang đến vài thứ nhỏ mà anh lính yêu cầu: một chút bắp cải, một chút cà rốt, một chút thịt bò... Cuối cùng anh lính đã nấu được một nồi cháo thịnh soạn chiêu đãi tất cả mọi người. Bài học là: Sự hợp tác, mặc dù chỉ từ những đóng góp nhỏ tưởng chừng rất đơn sơ tầm thường, nhưng lại có thể tạo ra thành quả đáng kể.
Các nhà nghiên cứu ngày nay đang sử dụng chiến thuật hợp tác tương tự như câu chuyện trên để xây dựng các siêu máy tính: đó là các máy rất mạnh có thể thực hiện hàng tỉ tính toán trong một giây. Hầu hết các siêu máy tính đều sử dụng phương pháp xử lý song song: chúng chứa một giàn các bộ vi xử lý cực nhanh, làm việc đồng loạt để giải quyết những bài toán phức tạp như dự báo thời tiết hoặc mô phỏng vụ nổ hạt nhân. Các siêu máy tính chế tạo bởi IBM như CRAY thường có giá tới hàng chục triệu đô la, quá đắt đối với ngân sách eo hẹp của một cơ sở nghiên cứu. Vì thế trong vài năm qua các nhà nghiên cứu ở các phòng thí nghiệm và các đại học đã tập trung theo hướng tự xây dựng siêu máy tính cho riêng mình bằng cách kết nối các PC rẻ tiền và viết phần mềm sao cho các máy tính thường này có thể giải quyết được các công việc phi thường.
Năm 1996 hai người trong chúng tôi (Hargrove và Hoffman) vấp phải một vấn đề khó trong công việc tại Phòng thí nghiệm Quốc gia Oak Ridge (ORNL). Chúng tôi cần phải vẽ bản đồ các vùng sinh thái toàn quốc. Nó được định nghĩa bởi các điều kiện môi trường: tất cả các vùng có cùng khí hậu, địa mạo và đặc trưng đất trong cùng một vùng sinh thái. Để tạo ra bản đồ có độ phân gải cao, chúng tôi chia quốc gia thành 7.8 triệu ô vuông, mỗi ô tương ứng với một vùng diện tích 1 km vuông. Trong mỗi ô chúng tôi phải xem xét cỡ 25 biến, bao gồm từ lượng mưa trung bình hàng tháng đến thành phần nitơ trong đất. Một PC hoặc một workstation đơn lẻ không thể thực hiện công việc này. Chúng tôi cần một siêu máy tính song song và chúng tôi có thể làm được nó.
Giải pháp của chúng tôi là xây dựng một cluster tính toán sử dụng các PC lỗi thời mà ORNL đã loại bỏ. Hệ thống được đặt tên lóng là Stone SouperComputer (máy tính cháo rừu) bởi vì chế tạo nó thực chất chẳng tốn xu nào, tuy nhiên nó đủ mạnh để tạo được các bản đồ vùng sinh thái chi tiết chưa từng thấy. Với một chi phí khiêm tốn, nhiều nhóm nghiên cứu khác thậm chí đã chế tạo được các cluster tính toán có thể so sánh với các siêu máy tính tốt nhất thế giới. Lợi thế về tỷ lệ giá cả trên hiệu suất của tính toán cluster đã thu hút sự quan tâm của nhiều công ty, tổ chức có nhu cầu tính toán những vấn đề phức tạp (ví dụ như giải mã gien người). Tóm lại, khái niệm cluster hứa hẹn cách mạng hoá lĩnh vực tính toán bằng cách trao năng lực xử lý to lớn cho bất kỳ nhóm nghiên cứu, trường học, hay doanh nghiệp nào muốn khai thác nó.

#1
 Đã gửi 01-01-2005 - 19:08
Đã gửi 01-01-2005 - 19:08
NangLuong
-
- Hiệp sỹ
-

- 2488 Bài viết
Thành viên Diễn đàn Toán.
#2
Đã gửi 01-01-2005 - 19:12
NangLuong
-
- Hiệp sỹ
-
- 2488 Bài viết
Thành viên Diễn đàn Toán.
Beowulf và Grendel
Ý tưởng liên kết các máy tính lại với nhau không phải là mới. Từ những năm 1950 và 1960 Không lực Mỹ đã thiết lập một mạng lưới các máy tính bóng đèn điện tử gọi là SAGE để đề phòng một cuộc tấn công hạt nhân của Liên Xô. Vào giữa những năm 1980 Tập đoàn Thiết bị Số đặt ra thuật ngữ "cluster" khi tích hợp các minicomputers VAX tầm trung thành một hệ thống lớn hơn. Các mạng của các workstation (các workstation nhìn chung không mạnh bằng các minicomputer nhưng nhanh hơn các PC) nhanh chóng trở nên thông dụng tại các viện nghiên cứu. Đến đầu những năm 1990 các nhà khoa học bắt đầu xem xét khả năng xây dựng các clusters từ các PC, một phần bởi giá các bộ vi xử lý đã trở nên khá rẻ, phần khác là vì giá thành thấp của Ethernet - một kỹ thuật vượt trội để kết nối các máy tính trong mạng cục bộ.
Các tiến bộ trong lĩnh vực phần mềm cũng đã mở đường cho sự phát triển của PC cluster. Vào những năm 1980 Unix nổi lên với tư cách một hệ điều hành lý tưởng cho các tính toán khoa học và kỹ thuật. Tuy nhiên, hệ điều hành cho các PC của Unix vẫn thiếu sức mạnh và thiếu linh hoạt. Năm 1991, sinh viên tốt nghiệp Linus Torvalds tạo ra Linux - một hệ điều hành giống Unix chạy trên PC. Torvalds đưa Linux lên internet cung cấp miễn phí, lập tức hàng trăm lập trình viên đã bắt tay vào cải tiến và hoàn thiện nó. Ngày nay Linux đã trở thành một hệ điều hành phổ biến rộng khắp, nó cũng chính là hệ điều hành lý tưởng cho PC cluster.
PC cluster đầu tiên ra đời năm 1994 tại Trung tâm Bay Không gian Gaddard của NASA. NASA lúc đó đang cố tìm kiếm phương thức ít tốn kém để giải quyết những vấn đề tính toán rắc rối thường gặp trong khoa học không gian và trái đất. Tổ chức không gian này cần một cỗ máy có thể thực hiện cỡ một gigaflops, nghĩa là thực hiện một tỷ phép tính dấu phẩy động một giây (phép tính ở đây tương đương với một tính toán đơn giản như phép cộng hoặc nhân). Tuy nhiên, tại thời điểm này, các siêu máy tính thương mại có thể làm điều đó có giá khoảng 1 triệu $, quá đắt cho chỉ một nhóm nghiên cứu.
Một người trong chúng tôi (Sterling) quyết định theo đuổi ý tưởng cấp tiến là xây dựng một cluster tính toán từ các PC. Sterling và đồng nghiệp của ông tại Goddard là D.J. Becker đã nối 16 PC lại với nhau sử dụng Linux và mạng Ethernet chuẩn, mỗi PC trong mạng chứa một chip vi xử lý 486 của Intel. Với các ứng dụng khoa học, PC cluster này cho hiệu suất 70 megaflops, tức là 70 triệu phép tính dấu phẩy động một giây. Mặc dù so với chuẩn hiện nay thế là rất khiêm tốn nhưng lúc bấy giờ tốc độ này không thấp hơn bao nhiêu so với các siêu máy tính thương mại loại nhỏ. Đặc biệt, chi phí cho PC cluster của chúng tôi chỉ tốn $40000, bằng một phần mười giá của máy tính thương mại hiệu suất tương đương.
Các nhà nghiên cứu tại NASA đặt tên cho cluster của họ là Beowulf, dựa theo tên của một nhân vật anh hùng thời trung cổ trong truyền thuyết, người đã đánh bại quái vật khổng lồ Grendel bằng cách xé toạc một cánh tay của sinh vật này. Từ đó trở đi cái tên này trở nên thông dụng để chỉ các cluster giá rẻ xây dựng từ các PC thông thường. Năm 1996 hai hệ Beowulf cluster tiếp theo xuất hiện: Đó là Hyglac (chế tạo bởi các nhà khoa học Viện Kỹ thuật California và Phòng thí nghiệm Jet Propulsion) và Loki (xây dựng bởi Phòng thí nghiệm Quốc gia Los Alamos). Mỗi cluster (tích hợp 16 Intel Pentium Pro microprocessor) đã đạt được hiệu suất một gigaflops với giá thành thấp hơn $50000, thoả mãn mục tiêu ban đầu của NASA.
Phương án Beowulf dường như là một giải pháp hoàn hảo cho vấn đề lập bản đồ các vùng sinh thái nước Mỹ của chúng tôi. Một workstation đơn lẻ chỉ có thể xử lý dữ liệu cho một phần nhỏ của bản đồ nhưng chúng tôi lại không thể chia các vùng khác nhau của nước Mỹ cho từng workstation chạy độc lập được - các dữ liệu môi trường của mỗi phần lãnh thổ phải được so sánh với nhau và xử lý đồng thời. Nói cách khác, chúng tôi cần một hệ thống xử lý song song. Vì thế năm 1996 chúng tôi gửi một bản đề xuất mua 64 PC mới chứa chip vi xử lý Pentium II cùng với cấu trúc của một siêu máy tính loại Beowulf. Lạy thánh Alas, ý tưởng này lại có vẻ đáng ngờ đối với các nhà xét duyệt ngân sách của ORNL và họ đã bác bỏ đề xuất của chúng tôi.
Không nản lòng, chúng tôi nghĩ một kế hoạch khác thay thế. Chúng tôi biết rằng các PC lỗi thời của US Department of Energy complex ở Oak Ridge thường xuyên được thay thế bởi các thế hệ mới hơn. Các PC cũ này được quảng cáo trên trang web nội bộ để bán như những thiết bị thừa. Chúng tôi đã kiểm tra và thấy có hàng trăm máy tính quá date như thế đang chờ loại bỏ. Có lẽ chúng tôi phải xây dựng hệ Beowulf của mình từ những máy mà chúng tôi có thể thu thập và tái sinh được. Chúng tôi xin một phòng tại ORNL trước đây là nhà chứa một cái máy tính mainframe cũ kỹ. Tiếp theo chúng tôi bắt đầu thu thập các PC thừa để tạo ra Stone SouperComputer.
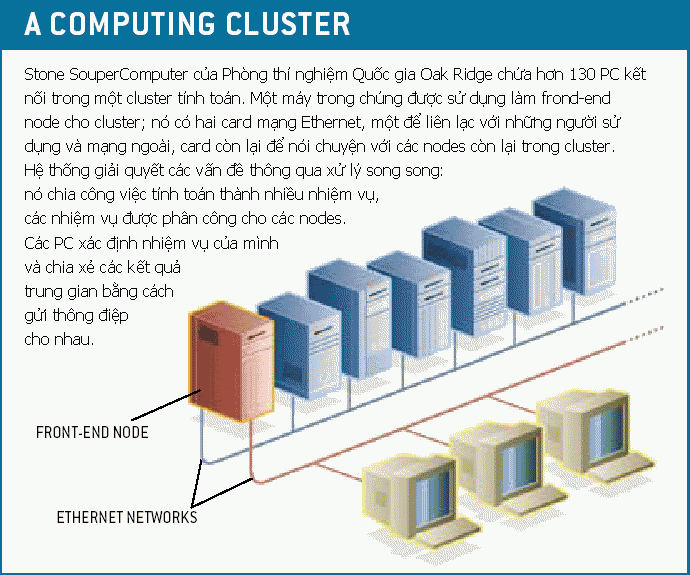
Sơ đồ cầu tạo một SuperComputer Cluster
Ý tưởng liên kết các máy tính lại với nhau không phải là mới. Từ những năm 1950 và 1960 Không lực Mỹ đã thiết lập một mạng lưới các máy tính bóng đèn điện tử gọi là SAGE để đề phòng một cuộc tấn công hạt nhân của Liên Xô. Vào giữa những năm 1980 Tập đoàn Thiết bị Số đặt ra thuật ngữ "cluster" khi tích hợp các minicomputers VAX tầm trung thành một hệ thống lớn hơn. Các mạng của các workstation (các workstation nhìn chung không mạnh bằng các minicomputer nhưng nhanh hơn các PC) nhanh chóng trở nên thông dụng tại các viện nghiên cứu. Đến đầu những năm 1990 các nhà khoa học bắt đầu xem xét khả năng xây dựng các clusters từ các PC, một phần bởi giá các bộ vi xử lý đã trở nên khá rẻ, phần khác là vì giá thành thấp của Ethernet - một kỹ thuật vượt trội để kết nối các máy tính trong mạng cục bộ.
Các tiến bộ trong lĩnh vực phần mềm cũng đã mở đường cho sự phát triển của PC cluster. Vào những năm 1980 Unix nổi lên với tư cách một hệ điều hành lý tưởng cho các tính toán khoa học và kỹ thuật. Tuy nhiên, hệ điều hành cho các PC của Unix vẫn thiếu sức mạnh và thiếu linh hoạt. Năm 1991, sinh viên tốt nghiệp Linus Torvalds tạo ra Linux - một hệ điều hành giống Unix chạy trên PC. Torvalds đưa Linux lên internet cung cấp miễn phí, lập tức hàng trăm lập trình viên đã bắt tay vào cải tiến và hoàn thiện nó. Ngày nay Linux đã trở thành một hệ điều hành phổ biến rộng khắp, nó cũng chính là hệ điều hành lý tưởng cho PC cluster.
PC cluster đầu tiên ra đời năm 1994 tại Trung tâm Bay Không gian Gaddard của NASA. NASA lúc đó đang cố tìm kiếm phương thức ít tốn kém để giải quyết những vấn đề tính toán rắc rối thường gặp trong khoa học không gian và trái đất. Tổ chức không gian này cần một cỗ máy có thể thực hiện cỡ một gigaflops, nghĩa là thực hiện một tỷ phép tính dấu phẩy động một giây (phép tính ở đây tương đương với một tính toán đơn giản như phép cộng hoặc nhân). Tuy nhiên, tại thời điểm này, các siêu máy tính thương mại có thể làm điều đó có giá khoảng 1 triệu $, quá đắt cho chỉ một nhóm nghiên cứu.
Một người trong chúng tôi (Sterling) quyết định theo đuổi ý tưởng cấp tiến là xây dựng một cluster tính toán từ các PC. Sterling và đồng nghiệp của ông tại Goddard là D.J. Becker đã nối 16 PC lại với nhau sử dụng Linux và mạng Ethernet chuẩn, mỗi PC trong mạng chứa một chip vi xử lý 486 của Intel. Với các ứng dụng khoa học, PC cluster này cho hiệu suất 70 megaflops, tức là 70 triệu phép tính dấu phẩy động một giây. Mặc dù so với chuẩn hiện nay thế là rất khiêm tốn nhưng lúc bấy giờ tốc độ này không thấp hơn bao nhiêu so với các siêu máy tính thương mại loại nhỏ. Đặc biệt, chi phí cho PC cluster của chúng tôi chỉ tốn $40000, bằng một phần mười giá của máy tính thương mại hiệu suất tương đương.
Các nhà nghiên cứu tại NASA đặt tên cho cluster của họ là Beowulf, dựa theo tên của một nhân vật anh hùng thời trung cổ trong truyền thuyết, người đã đánh bại quái vật khổng lồ Grendel bằng cách xé toạc một cánh tay của sinh vật này. Từ đó trở đi cái tên này trở nên thông dụng để chỉ các cluster giá rẻ xây dựng từ các PC thông thường. Năm 1996 hai hệ Beowulf cluster tiếp theo xuất hiện: Đó là Hyglac (chế tạo bởi các nhà khoa học Viện Kỹ thuật California và Phòng thí nghiệm Jet Propulsion) và Loki (xây dựng bởi Phòng thí nghiệm Quốc gia Los Alamos). Mỗi cluster (tích hợp 16 Intel Pentium Pro microprocessor) đã đạt được hiệu suất một gigaflops với giá thành thấp hơn $50000, thoả mãn mục tiêu ban đầu của NASA.
Phương án Beowulf dường như là một giải pháp hoàn hảo cho vấn đề lập bản đồ các vùng sinh thái nước Mỹ của chúng tôi. Một workstation đơn lẻ chỉ có thể xử lý dữ liệu cho một phần nhỏ của bản đồ nhưng chúng tôi lại không thể chia các vùng khác nhau của nước Mỹ cho từng workstation chạy độc lập được - các dữ liệu môi trường của mỗi phần lãnh thổ phải được so sánh với nhau và xử lý đồng thời. Nói cách khác, chúng tôi cần một hệ thống xử lý song song. Vì thế năm 1996 chúng tôi gửi một bản đề xuất mua 64 PC mới chứa chip vi xử lý Pentium II cùng với cấu trúc của một siêu máy tính loại Beowulf. Lạy thánh Alas, ý tưởng này lại có vẻ đáng ngờ đối với các nhà xét duyệt ngân sách của ORNL và họ đã bác bỏ đề xuất của chúng tôi.
Không nản lòng, chúng tôi nghĩ một kế hoạch khác thay thế. Chúng tôi biết rằng các PC lỗi thời của US Department of Energy complex ở Oak Ridge thường xuyên được thay thế bởi các thế hệ mới hơn. Các PC cũ này được quảng cáo trên trang web nội bộ để bán như những thiết bị thừa. Chúng tôi đã kiểm tra và thấy có hàng trăm máy tính quá date như thế đang chờ loại bỏ. Có lẽ chúng tôi phải xây dựng hệ Beowulf của mình từ những máy mà chúng tôi có thể thu thập và tái sinh được. Chúng tôi xin một phòng tại ORNL trước đây là nhà chứa một cái máy tính mainframe cũ kỹ. Tiếp theo chúng tôi bắt đầu thu thập các PC thừa để tạo ra Stone SouperComputer.
Sơ đồ cầu tạo một SuperComputer Cluster
#3
Đã gửi 01-01-2005 - 19:14
NangLuong
-
- Hiệp sỹ
-
- 2488 Bài viết
Thành viên Diễn đàn Toán.
"Chop Shop" số
Chiến lược của tính toán song song là "chia để trị" (divide and conquer). Một hệ thống xử lý song song phân chia bài toán phức tạp thành các phần nhiệm vụ nhỏ. Các nhiệm vụ này được phân công cho các node của hệ thống (ví dụ: là các PC trong Beowulf cluster) để xử lý đồng thời. Hiệu quả của xử lý song song phụ thuộc nhiều vào bản chất của bài toán. Một điều quan trọng đáng quan tâm là các node cần liên lạc với nhau (để phối hợp công việc của chúng và chia xẻ kết quả trung gian) nhiều hay ít trong quá trình tính toán? Với một số bài toán thể loại fine-grained, sự đòi hỏi liên lạc giữa các node là rất thường xuyên, vì thế ta cần phải chia bài toán thành vô số các công việc rất nhỏ. Những bài toán này không phù hợp lắm với xử lý song song. Ngược lại các bài toán thể loại coarse-grained có thể chia thành các miếng tương đối lớn. Những bài toán này không đòi hỏi nhiều liên lạc giữa các node và do vậy chúng có thể dễ dàng được giải quyết bởi hệ thống xử lý song song.
Bất kỳ ai xây dựng một Beowulf cluster cũng phải bắt đầu bằng việc thiết kế hệ thống. Để kết nối các PC, các nhà nghiên cứu có thể sử dụng hoặc các mạng Ethernet chuẩn hoặc các mạng chuyên biệt nhanh hơn như Myrinet. Do không có nhiều ngân sách, chúng tôi sử dụng Ethernet, vì nó là miễn phí. Chúng tôi chọn một PC làm front-end node cho cluster và lắp hai card Ethernet vào máy đó. Một card để liên lạc với ngưòi sử dụng bên ngoài, và card còn lại để làm việc với các node còn lại trong mạng cục bộ. Hai thư viện message-passing thông dụng nhất là Message-Passing Interface (MPI) và Parallel Virtual Machine (PVM), hai thư viện này đều được phát hành miễn phí trên internet. Chúng tôi sử dụng cả hai hệ trên cho Stone SouperComputer.
Đa số các Beowulf cluster là đồng nhất, tức là chúng bao gồm các PC có cấu hình và chíp vi xử lý giống nhau. Sự đồng đều này làm đơn giản hoá việc quản lý và sử dụng cluster nhưng không phải đây là một đòi hỏi bắt buộc. Stone SouperComputer của chúng tôi chứa đựng nhiều loại vi xử lý với đủ kiểu tốc độ vì chúng tôi có ý định sử dụng bất kỳ thứ gì chúng tôi có thể tìm được. Chúng tôi bắt đầu với các PC chứa procesor Intel 486, sau đó chỉ bổ sung các máy Pentium với ít nhất 32 megabyte RAM và 200 megabyte đĩa cứng.
Hiếm khi có một cái máy đến với chúng tôi mà đạt tiêu chuẩn tối thiểu, mà thông thường chúng tôi phải kết hợp những bộ phận tốt nhất của vài PC để được một node cho cluster. Việc chuyển đổi các phụ tùng máy tính này làm phòng chúng tôi giống như một "chop shop" số (chop shop là từ lóng dùng chỉ các cửa hiệu bán đồ phụ tùng xe hơi chôm chỉa). Mỗi khi chúng tôi rã một cái máy tính chúng tôi lại có cảm giác mong đợi y như những đứa trẻ khi mở hộp quà sinh nhật: liệu cái máy này sẽ có một ổ cứng lớn, có nhiều bộ nhớ hay (tốt hơn cả) là một motherboard mới ngưòi ta vô tình cho chúng tôi? Phòng của chúng tôi tại Oak Ridge đã biến thành một nhà xác chất đầy xác của các máy tính chết. Trung bình cần khoảng năm PC cũ để chúng tôi làm được một node tốt.
Mỗi khi có một node mới nối thêm vào cluster, việc đầu tiên là chúng tôi tải hệ điều hành Linux vào trong máy. Trước đó chúng tôi đã tìm ra cách làm sao để loại bỏ việc cài đặt bàn phím và màn hình cho mỗi node. Chúng tôi chũng chế ra thiết bị di động "crash carts" có thể xoay và cắm vào các node trục trặc để xác định tình trạng của nó. Cuối cùng ai đó đã mua cho chúng tôi một cái kệ để chúng tôi sắp xếp bộ sự tập phần cứng của mình. Stone SouperComputer chạy dòng mã đầu tiên vào đầu năm 1997, và đến tháng 5 năm 2001 nó đã chứa 133 node, trong đó có 75 PC với bộ vi xử lý Intel 486, có 53 máy nhanh hơn với chip Pentium và 5 máy nhanh hơn nữa là các workstation Alpha chế tạo bởi Compaq.
Việc nâng cấp Stone SouperComputer rất đơn giản, chúng tôi thay thế các node chậm nhất trước. Không như các siêu máy tính thương mại, hiệu suất của Stone SouperComputer không ngừng được cải tiến bởi chúng tôi có nguồn cung cấp thiết bị nâng cấp miễn phí không bao giờ hết.
Chiến lược của tính toán song song là "chia để trị" (divide and conquer). Một hệ thống xử lý song song phân chia bài toán phức tạp thành các phần nhiệm vụ nhỏ. Các nhiệm vụ này được phân công cho các node của hệ thống (ví dụ: là các PC trong Beowulf cluster) để xử lý đồng thời. Hiệu quả của xử lý song song phụ thuộc nhiều vào bản chất của bài toán. Một điều quan trọng đáng quan tâm là các node cần liên lạc với nhau (để phối hợp công việc của chúng và chia xẻ kết quả trung gian) nhiều hay ít trong quá trình tính toán? Với một số bài toán thể loại fine-grained, sự đòi hỏi liên lạc giữa các node là rất thường xuyên, vì thế ta cần phải chia bài toán thành vô số các công việc rất nhỏ. Những bài toán này không phù hợp lắm với xử lý song song. Ngược lại các bài toán thể loại coarse-grained có thể chia thành các miếng tương đối lớn. Những bài toán này không đòi hỏi nhiều liên lạc giữa các node và do vậy chúng có thể dễ dàng được giải quyết bởi hệ thống xử lý song song.
Bất kỳ ai xây dựng một Beowulf cluster cũng phải bắt đầu bằng việc thiết kế hệ thống. Để kết nối các PC, các nhà nghiên cứu có thể sử dụng hoặc các mạng Ethernet chuẩn hoặc các mạng chuyên biệt nhanh hơn như Myrinet. Do không có nhiều ngân sách, chúng tôi sử dụng Ethernet, vì nó là miễn phí. Chúng tôi chọn một PC làm front-end node cho cluster và lắp hai card Ethernet vào máy đó. Một card để liên lạc với ngưòi sử dụng bên ngoài, và card còn lại để làm việc với các node còn lại trong mạng cục bộ. Hai thư viện message-passing thông dụng nhất là Message-Passing Interface (MPI) và Parallel Virtual Machine (PVM), hai thư viện này đều được phát hành miễn phí trên internet. Chúng tôi sử dụng cả hai hệ trên cho Stone SouperComputer.
Đa số các Beowulf cluster là đồng nhất, tức là chúng bao gồm các PC có cấu hình và chíp vi xử lý giống nhau. Sự đồng đều này làm đơn giản hoá việc quản lý và sử dụng cluster nhưng không phải đây là một đòi hỏi bắt buộc. Stone SouperComputer của chúng tôi chứa đựng nhiều loại vi xử lý với đủ kiểu tốc độ vì chúng tôi có ý định sử dụng bất kỳ thứ gì chúng tôi có thể tìm được. Chúng tôi bắt đầu với các PC chứa procesor Intel 486, sau đó chỉ bổ sung các máy Pentium với ít nhất 32 megabyte RAM và 200 megabyte đĩa cứng.
Hiếm khi có một cái máy đến với chúng tôi mà đạt tiêu chuẩn tối thiểu, mà thông thường chúng tôi phải kết hợp những bộ phận tốt nhất của vài PC để được một node cho cluster. Việc chuyển đổi các phụ tùng máy tính này làm phòng chúng tôi giống như một "chop shop" số (chop shop là từ lóng dùng chỉ các cửa hiệu bán đồ phụ tùng xe hơi chôm chỉa). Mỗi khi chúng tôi rã một cái máy tính chúng tôi lại có cảm giác mong đợi y như những đứa trẻ khi mở hộp quà sinh nhật: liệu cái máy này sẽ có một ổ cứng lớn, có nhiều bộ nhớ hay (tốt hơn cả) là một motherboard mới ngưòi ta vô tình cho chúng tôi? Phòng của chúng tôi tại Oak Ridge đã biến thành một nhà xác chất đầy xác của các máy tính chết. Trung bình cần khoảng năm PC cũ để chúng tôi làm được một node tốt.
Mỗi khi có một node mới nối thêm vào cluster, việc đầu tiên là chúng tôi tải hệ điều hành Linux vào trong máy. Trước đó chúng tôi đã tìm ra cách làm sao để loại bỏ việc cài đặt bàn phím và màn hình cho mỗi node. Chúng tôi chũng chế ra thiết bị di động "crash carts" có thể xoay và cắm vào các node trục trặc để xác định tình trạng của nó. Cuối cùng ai đó đã mua cho chúng tôi một cái kệ để chúng tôi sắp xếp bộ sự tập phần cứng của mình. Stone SouperComputer chạy dòng mã đầu tiên vào đầu năm 1997, và đến tháng 5 năm 2001 nó đã chứa 133 node, trong đó có 75 PC với bộ vi xử lý Intel 486, có 53 máy nhanh hơn với chip Pentium và 5 máy nhanh hơn nữa là các workstation Alpha chế tạo bởi Compaq.
Việc nâng cấp Stone SouperComputer rất đơn giản, chúng tôi thay thế các node chậm nhất trước. Không như các siêu máy tính thương mại, hiệu suất của Stone SouperComputer không ngừng được cải tiến bởi chúng tôi có nguồn cung cấp thiết bị nâng cấp miễn phí không bao giờ hết.
#4
Đã gửi 01-01-2005 - 19:17
NangLuong
-
- Hiệp sỹ
-
- 2488 Bài viết
Thành viên Diễn đàn Toán.
Giải bài toán song song
Việc lập trình song song đòi hỏi nhiều kỹ năng và óc sáng tạo hơn so với việc lắp ráp phần cứng hệ Beowulf. Mô hình lập trình cluster thông dụng nhất là mô hình master-slave. Trong đó, một node (được giao nhiệm vụ làm chủ - master) chỉ đạo các node khác (đóng vai trò các người làm - slave) thực hiện công việc tính toán. Chúng tôi chạy cùng một chương trình trên tất cả các máy trong Stone SouperComputer. Trong chương trình đó có những phần mã khác nhau dành cho node-master hoặc cho các node-slave. Mỗi processor trong cluster thực hiện chỉ phần mã tương ứng dành cho nó. Các lỗi lập trình có thể gây ra những hiệu ứng đổ bể hàng loạt, vì một node nào đó bị lỗi sẽ làm lệch hướng các node khác. Phân loại các trường hợp xảy ra để xác định lỗi nói chung là khó.
Một thách thức khác là làm sao cân bằng khối lượng công việc giữa các node. Vì Stone SouperComputer chứa nhiều chip vi xử lý với tốc độ rất khác nhau nên chúng tôi không thể chia đều công việc cho các node: nếu chúng tôi làm thế, các node-nhanh sẽ nhàn rỗi khá lâu vì chúng phải chờ các node-chậm xử lý công việc. Thay vì chia đều công việc, chúng tôi phát triển một thuật toán cho phép node-master gửi thêm dữ liệu tới các node-slave-nhanh mỗi khi chúng hoàn thành nhiệm vụ. Với phương cách dàn xếp cân bằng này, các node-nhanh làm nhiều công việc hơn, nhưng các node-chậm cũng có đóng góp nhất định vào hiệu suất của hệ.
Bước đầu tiên của chúng tôi trong việc giải quyết bài toán lập bản đồ vùng sinh thái là tổ chức một lượng khổng lồ dữ liệu: 25 đặc trưng môi trường của 7.8 triệu ô của lục địa Mỹ. Chúng tôi tạo một không gian dữ liệu 25 chiều, trong đó mỗi chiều biểu diễn một biến (nhiệt độ trung bình, lượng mưa, đặc trưng đất, v.v.). Tiếp theo chúng tôi đồng nhất mỗi ô trên bản đồ với một điểm tương ứng trong không gian dữ liệu. Hai điểm gần nhau trong không gian dữ liệu có các đặc trưng môi trường tương tự và vì thế được phân loại vào cùng một vùng sinh thái. Sự gần gũi về địa lý không quan trọng trong kiểu phân loại này; ví dụ nếu hai đỉnh núi có môi trường rất giống nhau thì mặc dù thực tế chúng cách nhau cả ngàn dặm nhưng các điểm của chúng trong không gian dữ liệu là rất gần nhau.
Mỗi khi tổ chức dữ liệu, chúng tôi phải xác định trước số các vùng sinh thái sẽ được hiển thị lên bản đồ quốc gia. Đầu tiên cluster sẽ gán cho mỗi vùng sinh thái một "vị trí hạt giống" trong không gian dữ liệu. Với mỗi điểm bất kỳ (trong 7.8 triệu điểm dữ liệu), hệ thống phải xác định xem nó nằm gần vị trí hạt giống nào nhất để gán nó vào vùng sinh thái tương ứng. Tiếp theo cluster tìm vị trí trung tâm của mỗi vùng sinh thái - vị trí trung bình của tất cả các điểm được gán vào vùng đó. Vị trí trung tâm tìm được sẽ thay thế vị trí hạt giống để làm điểm định nghiã cho một vùng sinh thái. Hệ thống lặp lại chu trình trên bằng cách gán lại các điểm dữ liệu vào các vùng sinh thái tùy thuộc vào khoảng cách từ chúng đến điểm trung tâm. Sau mỗi vòng lặp, mỗi vùng sinh thái sẽ có một vị trí trung tâm mới. Toàn bộ quá trình kết thúc khi các điểm dữ liệu được phân loại ổn định, tức là không thay đổi vùng sinh thái của mình nữa.
Công việc lập bản đồ rất phù hợp với xử lý song song bởi vì các node khác nhau trong cluster có thể làm việc độc lập trên những tập hợp con của 7.8 triệu điểm dữ liệu. Sau mỗi vòng lặp các node-slave gửi kết quả tính toán của chúng cho node-master, node này thu thập dữ liệu để xác định các vị trí trung tâm mới cho mỗi vùng sinh thái. Node-master gửi thông tin này trở lại cho các node-slave để tiếp tục tính toán vòng tiếp theo. Xử lý song song cũng hữu ích trong việc chọn lựa các vị trí hạt giống tốt nhất khi bắt đầu công việc. Chúng tôi nghĩ ra một thuật toán cho phép các node trong Stone SouperComputer cùng xác định các điểm dữ liệu phân tán rộng nhất để chọn làm các vị trí hạt giống. Nếu cluster khởi đầu với vị trí hạt giống tốt thì số vòng lặp hơn hệ thống cần phải thực hiện sẽ ít hơn.
Kết quả mà chúng tôi thu được là một loạt bản đồ nước Mỹ, trong đó mỗi vùng sinh thái được tô một màu khác nhau. Chúng tôi đã tạo các bản đồ có độ chi tiết từ chia chỉ 4 vùng sinh thái đến chia thành 5000 vùng sinh thái. Các bản đồ chia ít vùng sinh thái tương đối đơn giản, chúng ta có thể phân biệt các vùng như bang Rocky Mountain, sa mạc Souuth-west. Các bản đồ chia thành hàng ngàn vùng sinh thái của chúng tôi phức tạp hơn bất cứ bản đồ phân loại môi trường nào trước đây. Vì nhiều loài thực vật và động vật chỉ có thể sống ở những vùng sinh thái riêng nên bản đồ của chúng tôi có thể hữu ích cho các nhà sinh thái nghiên cứu các loài quí hiếm.
Stone SouperComputer cũng có thể cho thấy các vùng sinh thái dịch chuyển như thế nào nếu các điều kiện môi trường thay đổi, chẳng hạn do hiệu ứng nóng lên toàn cầu. Chúng tôi sử dụng các dự án dự báo khí hậu của các nhóm nghiên cứu khác để tiên đoán bản đồ sinh thái nước Mỹ vào năm 2099. Kết quả là, đến cuối thế kỷ này môi trường ở Pittsburgh sẽ giống như Atlanta ngày nay, và môi trường ở Minneapolis sẽ giống St. Louis trong thời điểm hiện tại.
Việc lập trình song song đòi hỏi nhiều kỹ năng và óc sáng tạo hơn so với việc lắp ráp phần cứng hệ Beowulf. Mô hình lập trình cluster thông dụng nhất là mô hình master-slave. Trong đó, một node (được giao nhiệm vụ làm chủ - master) chỉ đạo các node khác (đóng vai trò các người làm - slave) thực hiện công việc tính toán. Chúng tôi chạy cùng một chương trình trên tất cả các máy trong Stone SouperComputer. Trong chương trình đó có những phần mã khác nhau dành cho node-master hoặc cho các node-slave. Mỗi processor trong cluster thực hiện chỉ phần mã tương ứng dành cho nó. Các lỗi lập trình có thể gây ra những hiệu ứng đổ bể hàng loạt, vì một node nào đó bị lỗi sẽ làm lệch hướng các node khác. Phân loại các trường hợp xảy ra để xác định lỗi nói chung là khó.
Một thách thức khác là làm sao cân bằng khối lượng công việc giữa các node. Vì Stone SouperComputer chứa nhiều chip vi xử lý với tốc độ rất khác nhau nên chúng tôi không thể chia đều công việc cho các node: nếu chúng tôi làm thế, các node-nhanh sẽ nhàn rỗi khá lâu vì chúng phải chờ các node-chậm xử lý công việc. Thay vì chia đều công việc, chúng tôi phát triển một thuật toán cho phép node-master gửi thêm dữ liệu tới các node-slave-nhanh mỗi khi chúng hoàn thành nhiệm vụ. Với phương cách dàn xếp cân bằng này, các node-nhanh làm nhiều công việc hơn, nhưng các node-chậm cũng có đóng góp nhất định vào hiệu suất của hệ.
Bước đầu tiên của chúng tôi trong việc giải quyết bài toán lập bản đồ vùng sinh thái là tổ chức một lượng khổng lồ dữ liệu: 25 đặc trưng môi trường của 7.8 triệu ô của lục địa Mỹ. Chúng tôi tạo một không gian dữ liệu 25 chiều, trong đó mỗi chiều biểu diễn một biến (nhiệt độ trung bình, lượng mưa, đặc trưng đất, v.v.). Tiếp theo chúng tôi đồng nhất mỗi ô trên bản đồ với một điểm tương ứng trong không gian dữ liệu. Hai điểm gần nhau trong không gian dữ liệu có các đặc trưng môi trường tương tự và vì thế được phân loại vào cùng một vùng sinh thái. Sự gần gũi về địa lý không quan trọng trong kiểu phân loại này; ví dụ nếu hai đỉnh núi có môi trường rất giống nhau thì mặc dù thực tế chúng cách nhau cả ngàn dặm nhưng các điểm của chúng trong không gian dữ liệu là rất gần nhau.
Mỗi khi tổ chức dữ liệu, chúng tôi phải xác định trước số các vùng sinh thái sẽ được hiển thị lên bản đồ quốc gia. Đầu tiên cluster sẽ gán cho mỗi vùng sinh thái một "vị trí hạt giống" trong không gian dữ liệu. Với mỗi điểm bất kỳ (trong 7.8 triệu điểm dữ liệu), hệ thống phải xác định xem nó nằm gần vị trí hạt giống nào nhất để gán nó vào vùng sinh thái tương ứng. Tiếp theo cluster tìm vị trí trung tâm của mỗi vùng sinh thái - vị trí trung bình của tất cả các điểm được gán vào vùng đó. Vị trí trung tâm tìm được sẽ thay thế vị trí hạt giống để làm điểm định nghiã cho một vùng sinh thái. Hệ thống lặp lại chu trình trên bằng cách gán lại các điểm dữ liệu vào các vùng sinh thái tùy thuộc vào khoảng cách từ chúng đến điểm trung tâm. Sau mỗi vòng lặp, mỗi vùng sinh thái sẽ có một vị trí trung tâm mới. Toàn bộ quá trình kết thúc khi các điểm dữ liệu được phân loại ổn định, tức là không thay đổi vùng sinh thái của mình nữa.
Công việc lập bản đồ rất phù hợp với xử lý song song bởi vì các node khác nhau trong cluster có thể làm việc độc lập trên những tập hợp con của 7.8 triệu điểm dữ liệu. Sau mỗi vòng lặp các node-slave gửi kết quả tính toán của chúng cho node-master, node này thu thập dữ liệu để xác định các vị trí trung tâm mới cho mỗi vùng sinh thái. Node-master gửi thông tin này trở lại cho các node-slave để tiếp tục tính toán vòng tiếp theo. Xử lý song song cũng hữu ích trong việc chọn lựa các vị trí hạt giống tốt nhất khi bắt đầu công việc. Chúng tôi nghĩ ra một thuật toán cho phép các node trong Stone SouperComputer cùng xác định các điểm dữ liệu phân tán rộng nhất để chọn làm các vị trí hạt giống. Nếu cluster khởi đầu với vị trí hạt giống tốt thì số vòng lặp hơn hệ thống cần phải thực hiện sẽ ít hơn.
Kết quả mà chúng tôi thu được là một loạt bản đồ nước Mỹ, trong đó mỗi vùng sinh thái được tô một màu khác nhau. Chúng tôi đã tạo các bản đồ có độ chi tiết từ chia chỉ 4 vùng sinh thái đến chia thành 5000 vùng sinh thái. Các bản đồ chia ít vùng sinh thái tương đối đơn giản, chúng ta có thể phân biệt các vùng như bang Rocky Mountain, sa mạc Souuth-west. Các bản đồ chia thành hàng ngàn vùng sinh thái của chúng tôi phức tạp hơn bất cứ bản đồ phân loại môi trường nào trước đây. Vì nhiều loài thực vật và động vật chỉ có thể sống ở những vùng sinh thái riêng nên bản đồ của chúng tôi có thể hữu ích cho các nhà sinh thái nghiên cứu các loài quí hiếm.
Stone SouperComputer cũng có thể cho thấy các vùng sinh thái dịch chuyển như thế nào nếu các điều kiện môi trường thay đổi, chẳng hạn do hiệu ứng nóng lên toàn cầu. Chúng tôi sử dụng các dự án dự báo khí hậu của các nhóm nghiên cứu khác để tiên đoán bản đồ sinh thái nước Mỹ vào năm 2099. Kết quả là, đến cuối thế kỷ này môi trường ở Pittsburgh sẽ giống như Atlanta ngày nay, và môi trường ở Minneapolis sẽ giống St. Louis trong thời điểm hiện tại.
#5
Đã gửi 01-01-2005 - 19:21
NangLuong
-
- Hiệp sỹ
-
- 2488 Bài viết
Thành viên Diễn đàn Toán.
Tương lai của Cluster
Theo truyền thống ngưòi ta đo hiệu suất của siêu máy tính dựa trên tiêu chuẩn tốc độ: tức là xem hệ thống chạy một chương trình chuẩn trong bao lâu. Tuy nhiên chúng tôi thích đánh giá hệ thống thông qua việc nó xử lý các ứng dụng thực tế hơn. Để đánh giá Stone SouperComputer, chúng tôi cho chạy bài toán lập bản đồ sinh thái trên siêu máy tính Intel Paragon tại ORNL. Đã có thời đây là cỗ máy tính nhanh nhất phòng thí nghiệm, hiệu suất cực đại của nó đạt 150 gigaflops. Kết quả cho thấy rằng thời gian chạy trên Paragon và trên Stone SouperComputer cơ bản là như nhau. Chúng tôi chưa bao giờ chính thức đo tốc độ cluster của chúng tôi, nhưng trên lý thuyết hệ có hiệu suất cực đại khoảng 1.2 gigaflops. Sự khéo léo trong thiết kế thuật toán song song nhiều khi quan trọng hơn tốc độ hoặc công suất: trong lĩnh vực khoa học non trẻ này, David và Goliath (hay Beowulf và Grendel) tiếp tục tranh tài trên một đấu trường bằng phẳng.
Kể từ khi chúng tôi xây dựng Stone SouperComputer, xu hướng Beowulf đã tăng tốc rất nhanh. Các cluster mới với những cái tên kỳ lạ như Grendel, Naegling, Megalon, Brahma, Avalon, Medusa, The Hive, đã đều đặn nâng hiệu suất với các máy ngày càng nhanh hơn và rẻ hơn. Cuối năm ngoái, 28 cluster PC, cluster workstation và cluster server đã được ghi vào danh sách 500 máy tính nhanh nhất thế giới. Cluster LosLobos của ĐH New Mexico chứa 512 chíp vi xử lý Intel Pentium III là hệ máy nhanh thứ 80, nó có hiệu suất 237 gigaflops. Cluster Cplant của Phòng thí nghiệm Quốc gia Sandia chứa 580 vi xử lý Compaq Alpha đứng vị trí thứ 84. Tổ chức Khoa học Quốc gia và Bộ Năng lượng Mỹ đang có kế hoạch xây dựng các cluster mạnh hơn có khả năng tính toán tới teraflops (một ngàn tỷ phép tính dấu phẩy động một giây), đủ sức cạnh tranh với các siêu máy tính nhanh nhất hành tinh http://diendantoanho...tyle_emoticons/default/image075.gif.
Các công ty máy tính lớn hiện nay bắt đầu bán những cluster cho các doanh nghiệp có nhu cầu tính toán nhiều. Ví dụ, IBM đang xây dựng một cluster chứa 1250 server cho công ty công nghệ sinh học NuTec Sciences, công ty này dự định sủ dụng siêu máy tính để nhận diện các gene gây bệnh. Một xu hướng quan trọng khác là phát triển mạng các PC để thực hiện một công việc tập thể. Một ví dụ là dự án SETI@home đưa ra bởi các nhà khoa học ĐH California ở Berkeley. Họ đang phân tích các tín hiệu trong không gian để tìm dấu hiệu về sự sống văn minh ngoài trái đất. SETI@home gửi các mảng dữ liệu qua Internet tới hơn 3 triệu PC, các PC này xử lý dữ liệu về các tín hiệu radio mỗi khi chúng rảnh. Một số chuyên gia trong công nghiệp máy tính tiên đoán rằng các nhà khoa học cuối cùng sẽ tạo được một "mạng lưới tính toán" làm việc giống như mạng lưới điện: người sử dụng có thể nhận năng lực xử lý dễ dàng như lấy điện hiện nay.
Trên tất cả, khái niệm Beowulf trao cho chúng ta một sức mạnh lớn. Nó đoạt lấy khả năng tính toán cấp cao từ một số ít cá nhân tổ chức có đặc quyền để trao cho những người có nguồn tài chính khiêm tốn. Các nhóm nghiên cứu, các trường học hoặc các doanh nghiệp nhỏ đều có thể xây dựng hoặc mua hệ Beowulf cho riêng mình. Nếu bạn quyết định ra nhập giai cấp vô sản xử lý song song, hãy liên hệ với chúng tôi qua trang web http://extremelinux.esd.ornl.gov/ và nói cho chúng tôi về các kinh nghiệm xây dựng Beowulf của bạn. Chúng ta sẽ thấy món cháo rìu thực là ngon miệng.
-----------------
 Các số liệu tính đến thời điểm giữa năm 2001 khi bài báo này được viết.
Các số liệu tính đến thời điểm giữa năm 2001 khi bài báo này được viết.
HẾT
Theo truyền thống ngưòi ta đo hiệu suất của siêu máy tính dựa trên tiêu chuẩn tốc độ: tức là xem hệ thống chạy một chương trình chuẩn trong bao lâu. Tuy nhiên chúng tôi thích đánh giá hệ thống thông qua việc nó xử lý các ứng dụng thực tế hơn. Để đánh giá Stone SouperComputer, chúng tôi cho chạy bài toán lập bản đồ sinh thái trên siêu máy tính Intel Paragon tại ORNL. Đã có thời đây là cỗ máy tính nhanh nhất phòng thí nghiệm, hiệu suất cực đại của nó đạt 150 gigaflops. Kết quả cho thấy rằng thời gian chạy trên Paragon và trên Stone SouperComputer cơ bản là như nhau. Chúng tôi chưa bao giờ chính thức đo tốc độ cluster của chúng tôi, nhưng trên lý thuyết hệ có hiệu suất cực đại khoảng 1.2 gigaflops. Sự khéo léo trong thiết kế thuật toán song song nhiều khi quan trọng hơn tốc độ hoặc công suất: trong lĩnh vực khoa học non trẻ này, David và Goliath (hay Beowulf và Grendel) tiếp tục tranh tài trên một đấu trường bằng phẳng.
Kể từ khi chúng tôi xây dựng Stone SouperComputer, xu hướng Beowulf đã tăng tốc rất nhanh. Các cluster mới với những cái tên kỳ lạ như Grendel, Naegling, Megalon, Brahma, Avalon, Medusa, The Hive, đã đều đặn nâng hiệu suất với các máy ngày càng nhanh hơn và rẻ hơn. Cuối năm ngoái, 28 cluster PC, cluster workstation và cluster server đã được ghi vào danh sách 500 máy tính nhanh nhất thế giới. Cluster LosLobos của ĐH New Mexico chứa 512 chíp vi xử lý Intel Pentium III là hệ máy nhanh thứ 80, nó có hiệu suất 237 gigaflops. Cluster Cplant của Phòng thí nghiệm Quốc gia Sandia chứa 580 vi xử lý Compaq Alpha đứng vị trí thứ 84. Tổ chức Khoa học Quốc gia và Bộ Năng lượng Mỹ đang có kế hoạch xây dựng các cluster mạnh hơn có khả năng tính toán tới teraflops (một ngàn tỷ phép tính dấu phẩy động một giây), đủ sức cạnh tranh với các siêu máy tính nhanh nhất hành tinh http://diendantoanho...tyle_emoticons/default/image075.gif.
Các công ty máy tính lớn hiện nay bắt đầu bán những cluster cho các doanh nghiệp có nhu cầu tính toán nhiều. Ví dụ, IBM đang xây dựng một cluster chứa 1250 server cho công ty công nghệ sinh học NuTec Sciences, công ty này dự định sủ dụng siêu máy tính để nhận diện các gene gây bệnh. Một xu hướng quan trọng khác là phát triển mạng các PC để thực hiện một công việc tập thể. Một ví dụ là dự án SETI@home đưa ra bởi các nhà khoa học ĐH California ở Berkeley. Họ đang phân tích các tín hiệu trong không gian để tìm dấu hiệu về sự sống văn minh ngoài trái đất. SETI@home gửi các mảng dữ liệu qua Internet tới hơn 3 triệu PC, các PC này xử lý dữ liệu về các tín hiệu radio mỗi khi chúng rảnh. Một số chuyên gia trong công nghiệp máy tính tiên đoán rằng các nhà khoa học cuối cùng sẽ tạo được một "mạng lưới tính toán" làm việc giống như mạng lưới điện: người sử dụng có thể nhận năng lực xử lý dễ dàng như lấy điện hiện nay.
Trên tất cả, khái niệm Beowulf trao cho chúng ta một sức mạnh lớn. Nó đoạt lấy khả năng tính toán cấp cao từ một số ít cá nhân tổ chức có đặc quyền để trao cho những người có nguồn tài chính khiêm tốn. Các nhóm nghiên cứu, các trường học hoặc các doanh nghiệp nhỏ đều có thể xây dựng hoặc mua hệ Beowulf cho riêng mình. Nếu bạn quyết định ra nhập giai cấp vô sản xử lý song song, hãy liên hệ với chúng tôi qua trang web http://extremelinux.esd.ornl.gov/ và nói cho chúng tôi về các kinh nghiệm xây dựng Beowulf của bạn. Chúng ta sẽ thấy món cháo rìu thực là ngon miệng.
-----------------
Các số liệu tính đến thời điểm giữa năm 2001 khi bài báo này được viết. HẾT

0 người đang xem chủ đề
0 thành viên, 0 khách, 0 thành viên ẩn danh

